Optical character recognition (OCR) involves electronically converting images of typed or printed text into machine-encoded text. This allows libraries and museums to make archived material electronically available to the public, saving valuable historical records and potentially helping to free up physical storage space.
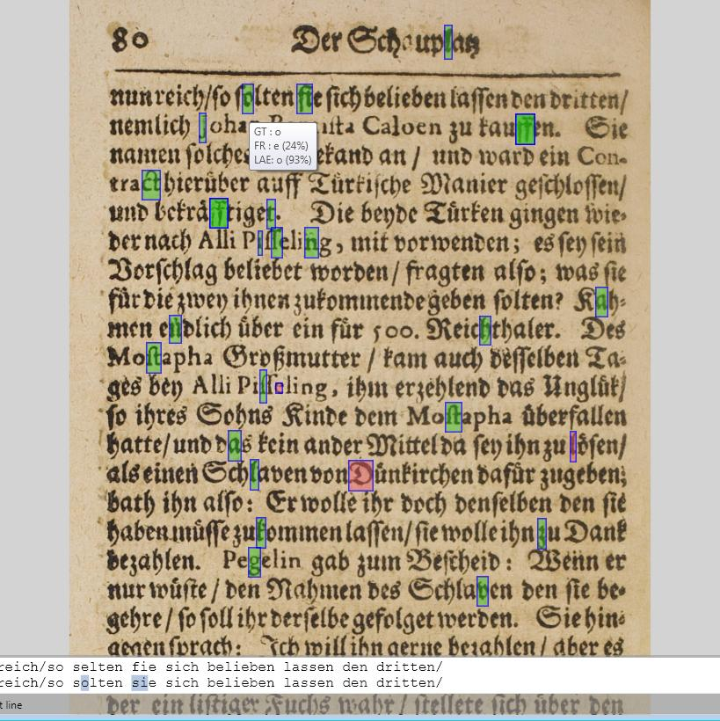
A challenge has been ensuring that an OCR scanner can "read" documents that might be falling apart and virtually illegible, or written in an unfamiliar script. This has been a big problem when digitising faded old newspapers. “Common OCR systems often fail to produce results good enough for automatic indexing,” explains Opto-Heritage project coordinator Alexander Goerke from Skilja in Germany. “But what we have shown in this project is that the digitisation of historical documents, especially old newspapers, can be improved. In order to really read and understand difficult texts though, we need to apply machine learning.”
The end result is OCR Accuracy Extension software, which Goerke says can achieve improvements of up to 15% on standard OCR results. “The lower the quality of the images, the higher the improvement,” he adds. “And since the software only uses image elements for the matching, it is also very fast.”
Libraries and institutions that provide digitised historical content through publicly available portals have expressed an interest in the Opto-Heritage innovation, and Goerke notes that discussions with potential customers are ongoing. “Most customers are in the public domain and this can take more time,” he says. In the meantime, Skilja and project partner Lumex are continuing to work together to refine the process and identify potential end users.
Learning to read
The Opto-Heritage project was launched in September 2014 with a focus on improving the digitisation of old documents and newspapers, as well as business archives. “A difficulty at the beginning was being able to apply this technology to specific use cases,” says Goerke. “To do this, we used a huge number of datasets to ‘train’ our algorithms and help move the system from prototype development towards being commercially ready. We needed the system to be familiar with millions of characters and thousands of pages, so that it was something that users could eventually just run themselves.”
Goerke compares this process to how self-learning algorithms are able to identify pictures. Once every aspect of a particular picture is logged, self-learning algorithms should be able to recognise the same image with a significantly lower quality, because they are able to pick up on certain similarities. The same goes for text. Historical manuscripts often contain hard-to-decipher Gothic script, and old newspapers tend to be full of small, poor quality print. “Just imagine that you see a document with very difficult to read text,” says Goerke. “In the beginning, you might be able to distinguish some of the more distinct characters. This will enable you to conclude the meaning of other characters, because you will have developed a feel for the characteristics of the writer.”
This is how unsupervised OCR machine learning works. Object detection and classification are used to create clusters of all possible characters on a specific page, whilst recognisable characters are automatically labelled and then applied in a second round to all the unknown characters. This helps the system to identify deteriorated or distorted samples. Incorrectly labelled characters can also be corrected when the full meaning of a particular word or phrase are known.
This process, which does not require human intervention, will hopefully mean that more archival material can be saved and made available for future generations.
Successful teamwork
Goerke credits much of the project’s success to the fruitful collaboration between his company Skilja (based in Germany) and Norwegian company Lumex. Blending their specific areas of expertise meant that a viable advanced OCR product could be developed efficiently.
“Lumex has been engaged in basic machine learning research for a long time, and we were able to apply some of their results to create market-ready products,” he explains. “The distribution of work was fairly straightforward: Lumex carried out the basic research and developed the early prototypes, whilst our developers created products and services that could be executed on a bigger scale.”
Goerke notes that Lumex also has good connections with libraries and digitisation companies, and that the partner played an important role in making contact and getting feedback from potential customers. On the commercial side, the project partners are currently at proof of concept stage, with a number of universities and libraries involved. Goerke and his colleagues are also talking with other possible customers, including Business Process Outsourcing companies (BPOs) that carry out digitisation as a service.
The project partners are reaping benefits from Opto-Heritage in other ways too. Skilja’s business focus is on developing solutions to retrieve information from documents, so they improved character recognition will advance positively. “Improving thematic analyses is the next step,” says Goerke. “And we are still cooperating with Lumex to solve the problem of low-quality characters.”
During the project, the team also identified document layouts (e.g. old newspapers) as a challenge for OCR. “Old newspapers often have very narrow columns,” he explains. “We found that we had to identify where the characters were before we could identify the words.” Work is therefore currently ongoing to add a layer of layout identification on top of character recognition. This will help to refine and improve their technology offer, and ultimately allow researchers to access cultural heritage easier and faster.
Partners: Lumex (Norway), Skilja (Germany)
Project ID: 9118 OPTO-HERITAGE (Eurostars)
Project duration: September 2014 to June 2018